
{kind=link}
{kind=link}
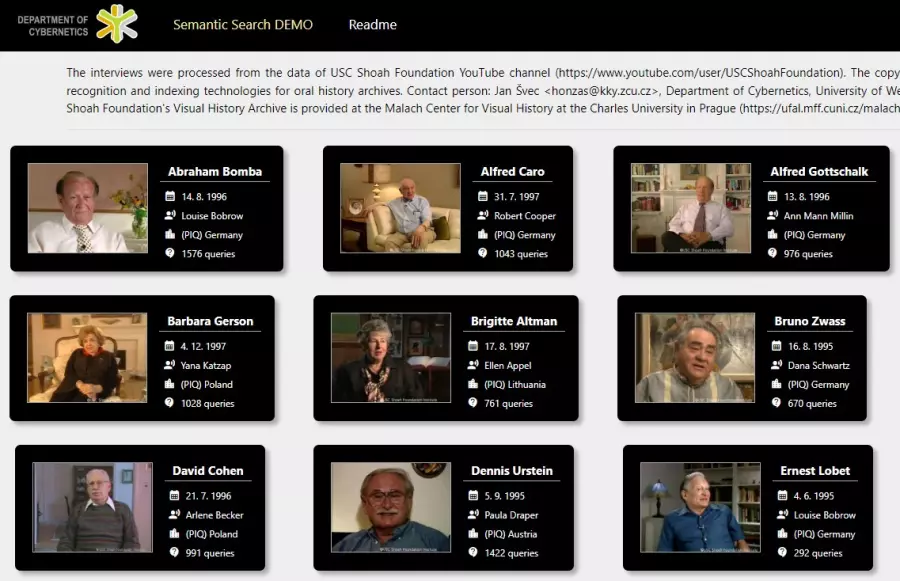
Tým vědců Fakulty aplikovaných věd Západočeské univerzity v Plzni dlouhodobě vyvíjí systémy rozpoznávání řeči pro audiovizuální archivy orální historie. Nedávno vědci představili nový systém pro porozumění těmto záznamům. Svědectví pamětníků budou díky němu snáze přístupná odborné i laické veřejnosti.
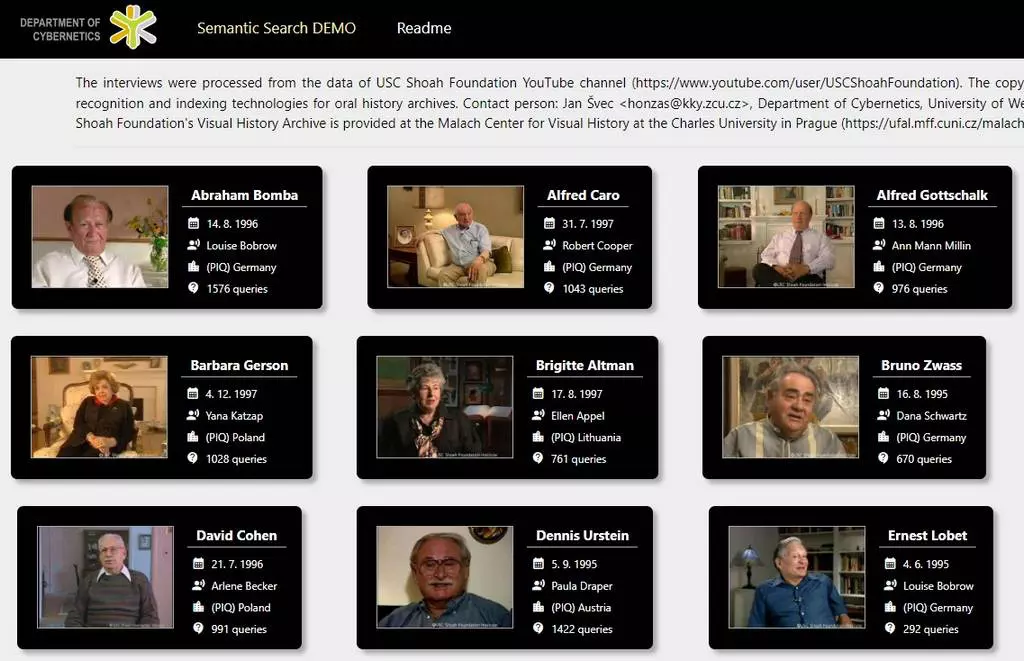
Vyhledávání pomocí položených otázek, tak se jmenuje nová technologie strojového učení vědců z katedry kybernetiky Fakulty aplikovaných věd (FAV), která umožňuje procházet dlouhé sekvence videozáznamů, a to na základě předem vygenerovaných otázek s časovým určením. Ty uživatele provedou obsahem videa a umožní přímou interakci s ním. Uživatelé tak mohou v archivech ústní historie pracovat intuitivním a interaktivním způsobem.
Software vyvinuli Jan Švec, Martin Bulín a Pavel Ircing z oddělení umělé inteligence katedry kybernetiky FAV a doktorandi Adam Frémund a Filip Polák. „Lidé ve videích mají tendenci dlouze vyprávět o svých zážitcích. Výsledkem jsou rozsáhlé a nestrukturované výpovědi, ve kterých je velmi obtížné vyhledávat. Je potřeba poslouchat od začátku, což zabere spoustu času. Pokud však otázky vytvoříme pomocí umělé inteligence a přiřadíme je k záznamu, lze požadovanou informaci najít právě podle nich. Po vyslechnutí dané sekvence pak záznam pokračuje dále,“ vysvětluje Jan Švec.
Vědci, kteří jsou součástí českého uzlu evropské výzkumné infrastruktury CLARIN, svou aplikaci představili letos v květnu na Londýnské King’s College v rámci workshopu EHRI-CLARIN, zaměřeném na lepší využitelnost ústních svědectví o holokaustu pro oblast vědy a výzkumu („Making Holocaust Oral Testimonies More Useable as Research Data“). Workshop potvrdil vhodnost aplikace pro použití v digitálních humanitních vědách.
Systémy pro rozpoznávání řeči a vyhledávání informací přitom vědci z katedry kybernetiky vyvíjejí už řadu let. „Vše začalo spoluprací se Stevenem Spielbergem, který po uvedení filmu Schindlerův seznam založil Nadaci šoa. Ta v letech 1994–2000 pořídila tisíce hodin výpovědí svědků holokaustu. Když záznamy nahrané na kazetách VHS zdigitalizovali, zjistili, že v nich není možné nic najít. A to odstartovalo výzkum, který pokračuje už více než dvacet let,“ ohlíží se Pavel Ircing zpět do doby, kdy tým katedry kybernetiky vyvinul software pro vyhledávání v rozsáhlém archivu USC Shoah Foundation.
Vše začalo projektem MALACH, financovaným americkou Národní vědeckou nadací (NSF) v letech 2001–2005. Tehdy byly položeny základy rozpoznávání řeči pro archivy orální historie. Projekt ministerstva kultury AMALACH, probíhající v letech 2012–15, pak plzeňští vědci využili pro vyvinutí nejen technologie rozpoznávání řeči pro angličtinu, ale i pro zpřístupnění vyhledávání ve svědectvích prostřednictvím webového portálu. Kromě toho mají odborníci z katedry kybernetiky na svém kontě například také technologii pro vyhledávání v archivu nahrávek a písemných dokumentů svědků komunistických represí Ústavu pro studium totalitních režimů, financovanou z programu NAKI ministerstva kultury.
Jejich nová technologie, založená na neuronových sítích, zahrnuje přizpůsobený převod řeči na text, metody vyhledávání, porozumění řeči a automatické titulky, díky čemuž je užitečná pro širokou škálu archivů a oborů. Především pak přináší funkci sémantického vyhledávání. Ta umožňuje hledat nikoli konkrétní slova nebo fráze, ale pasáže s významem souvisejícím s hledanou frází. To výrazně zvyšuje šanci na nalezení relevantních informací, protože dotazy nejsou omezeny na jedno klíčové slovo.
Funkci sémantického vyhledávání vědci navíc rozšířili tak, aby umožňovala také hlasové dotazy, a to jak v angličtině, tak v češtině. Řeč je rozpoznána technologií SpeechCloud, vyvinutou týmem z katedry kybernetiky, a rozpoznaný výrok je v reálném čase automaticky přeložen do angličtiny. „Naším konečným cílem je, aby uživatelé mohli komunikovat s osobou ve videu pomocí svého vlastního hlasu a vlastního jazyka,“ konstatuje Jan Švec. V budoucnu by proto tým rád rozšířil sadu podporovaných jazyků a přidal syntézu řeči. Uživatelé tak budou moci položit otázku ve svém preferovaném jazyce a ve stejném jazyce získat odpověď, bez ohledu na původní jazyk svědectví. Za tímto účelem už vědci z katedry kybernetiky FAV začali spolupracovat s jazykovědci a historiky v Itálii na vývoji italského rozpoznávače řeči. Workshopu EHRI-CLARIN se zúčastnili rovněž zástupci United States Holocaust Memorial Museum ve Washingtonu, kteří o technologii sémantického vyhledávání projevili zájem. Navázání spolupráce je jedním z výsledků londýnského workshopu.
Technologie tak otevírá badatelským či vzdělávacím účelům bohatou škálu záznamů orální historie z archivů po celém světě. „Mohla by být použita téměř pro jakékoli svědectví, včetně nejnovějších mediálních formátů, jako jsou podcasty a vysílané zprávy. Obecně by se dala použít také na jakákoli textová data, jako jsou naskenované dokumenty, což otevírá spoustu možností,“ přibližuje další formy využití Martin Bulín.
Demo verze aplikace je volně dostupná. Využívá výpovědi v angličtině publikované na YouTube kanálu USC Shoah Foundation. Celý mnohojazyčný archiv výpovědí svědků holokaustu USC Shoah Foundation je přístupný prostřednictvím Centra vizuální historie Malach na UK v Praze.
Prezentace Jan Švece a Martina Bulína na EHRI-CLARIN workshopu v Londýně zaujala i celoevropskou centrálu výzkumné infrastruktury CLARIN a článek o výzkumu prováděném na katedře kybernetiky FAV vyšel jako tzv. Clarin Impact Story.
Zdroj: Západočeská univerzita v Plzni
- Autor článku: ne
- Zdroj: Západočeská univerzita v Plzni